Towards Optimal Training Distribution for Photo-to-Face Models

This presentation was delivered at the Center for Advanced Signal and Image Sciences (CASIS) 28th Annual Workshop on 5 June 2024, which was held at the Lawrence Livermore National Laboratory.
Authors: Igor Borovikov and Karine Levonyan
How do we best construct game avatars from photos?
There’s a great deal of interest in personalizing game avatars with photos of players’ faces. Training an ML model to predict 3D facial parameters from a photo requires abundant training data.
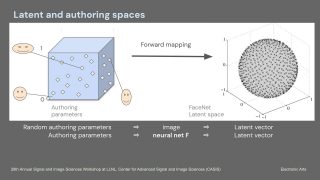
In games, the training data for photo-to-parameters ML models is synthetic so as to circumvent legal, licensing, and copyright issues. The training data consists of rendered images and the corresponding facial parameters. Randomizing the authoring parameters within some plausible distribution allows us to create realistic heads and train accurate photo-to-parameters models. This approach is well-established. However, some challenges remain.
A large volume of data is needed to prevent overfitting. Also, the distribution of parameters for training may be biased due to the design decisions. The biases may lead to lower accuracy for some faces and require a variety of data to overcome overfitting, which results in longer training cycles.
This presentation discusses a work in progress with an optimized view of the training data. It assumes fewer "sufficiently different" yet realistic human faces to better approximate distributions in the wild. The minimality and realism come from using latent spaces of FaceNet (or a similar DNN) used for facial recognition. The initial training dataset undergoes filtering to spread embedding vectors uniformly with a predefined distance when mapped to the latent space of FaceNet (i.e., we drop faces that are too similar).
The presentation discusses the proposed approach's challenges, advantages, and early results.