Imitation Learning with Concurrent Actions in 3D Games
SEED - Deep Learning

One of the pillars of SEED is to explore what is possible with new types of AI in future games. As part of this we've been developing novel deep reinforcement learning techniques to create self-learning agents with new engaging behaviors.
This is a first technical post about the reinforcement learning architecture that controls these self-learning agents. The full details can be found in our paper.
Deep Reinforcement Learning
Deep reinforcement learning is a new machine learning discipline that utilizes the power of reinforcement learning and deep neural networks in order to train agents to play imperfect information games. Recent work in this field has demonstrated that self-learning agents can be trained to play a number of complex games including Atari 2600 games, Doom, Dota 2, and Go.
Reinforcement learning agents are generally limited to carrying out one action at a time, due to the nature of the neural network architecture and the way they are trained. As such, agents often encounter situations where they are forced to choose one out of many actions, when in reality the optimum solution is to perform multiple actions at once; such as moving forward whilst turning. Indeed, certain behaviors will never emerge when an agent is limited to performing only one action at a time.
This problem is typically solved, in part, by expanding the set of actions such that all action combinations are explicitly modeled as new discrete actions, i.e. adding moving forward whilst turning right as an additional action. This method works well when the number of meaningful action combinations is small, but becomes infeasible when simulating the actions that are possible with a modern game controller (Figure 1), where the number of action combinations may exceed 1,000,000.
Figure 1: Large and complex action set in Battlefield 1.
When using large expanded action sets such as this, the entangled action representations make it much harder for the agent to learn the value of each of the true actions. The network controlled agent has to learn a disentangled version of the action set in order to understand the similarities between certain actions. To get around the problem associated with this explosion of action combinations, we present a novel technique that allows multiple actions to be selected at once whilst only modelling individual actions from the smaller, original action set.
Imitation Learning
We have also developed an imitation learning technique that provides a 4x improvement in training speed by having the agent learn useful behaviors by imitating the play style of an expert human player. Our experiments show that this significantly reduces the amount of time the agent spends performing seemingly random behaviors at the beginning of training. Further, we apply a combination of both imitation- and reinforcement learning to ensure that the agent also learns from its own experience.
We start the training phase using a mixture of 50/50 imitation learning and reinforcement learning, but gradually decay the contribution of imitation learning to 0 percent over time. We use a batched, synchronous version of A3C, modified to allow for concurrent discrete actions. The basic multi-action imitation learning (MAIL) network architecture can be seen in Figure 2 (details related to how to train the multi-action policy can be found in our paper).
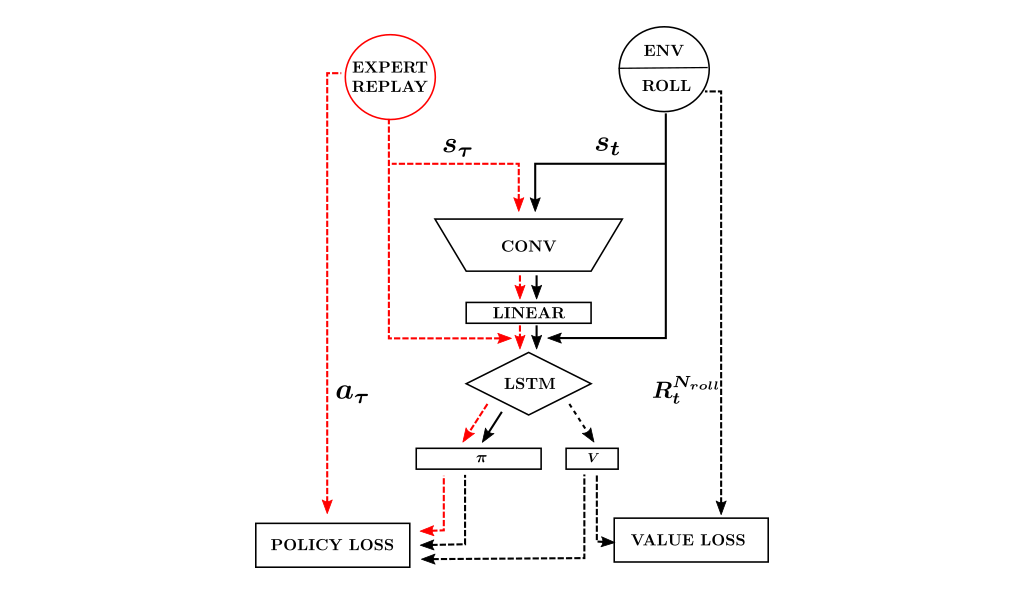
Figure 2: MAIL neural network architecture. Solid black lines represent the flow of data during inference. Dashed lines represent the flow of data during training.
MAIL significantly increases both the training speed and final performance of the agent when evaluated in an in-house 3D test game environment (see video). In this game, the agent strives to protect the blue-tinted region-of-interest by shooting the attacking red enemy bots. These red bots are greater in number but fire at a slower rate than the agent and use a simple classical game AI. The agent is able to replenish its health and ammunition by picking up red and green boxes respectively.
With no access to navigation meshes or other navigation systems, the agent relies on its neural network model to succeed. Despite this, the agent navigates the village with ease, without walking into buildings. The movement and actions performed by the agent often end up being remarkably similar to that of human gameplay, even though imitation learning is only used for a short period of time at the beginning of training.
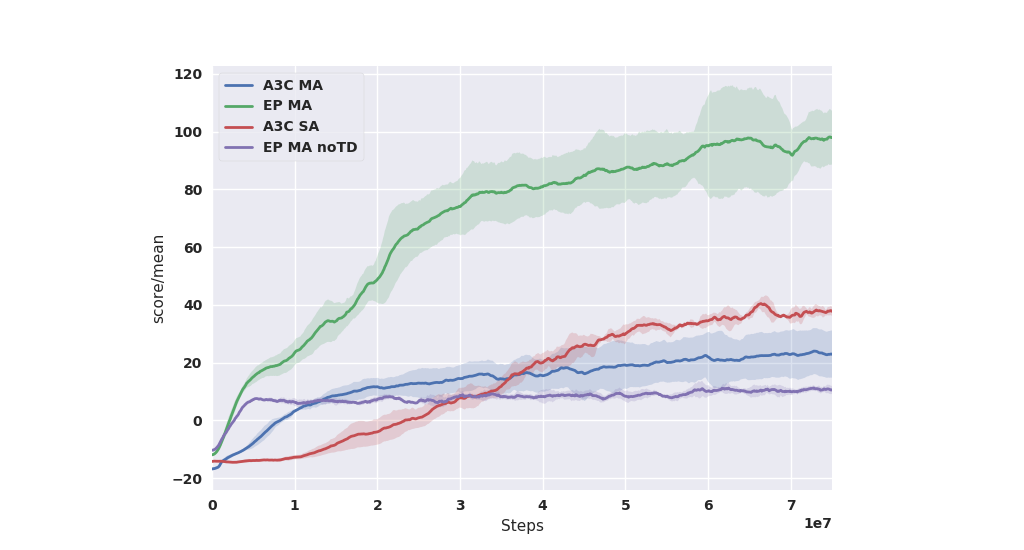
Figure 3: MAIL (green) significantly out-performs other techniques. Multi-Action (MA) RL (blue). IL and MA without RL (purple). Single-Action RL (red). The mean and standard deviation over 5 runs are shown for each result. Further details can be found in our paper.
Interestingly, the behavior of the trained MAIL agent is distinctly modal in nature. Its behavior changes significantly depending upon the agents current state. Certain triggers, such as the agent running low on ammo, cause the agent to drastically alter its style of play. This behavior arises naturally without deliberately partitioning the network to facilitate such behavior, i.e. using concepts such as manager networks.
With even more efficient training techniques, deeper networks with simple architectures might be capable of much higher level reasoning than is currently observed. Examples of some observed behaviors include: searching for the region-of-interest, searching for ammo/health, patrolling the region-of-interest, attacking enemies, fleeing enemies due to low health/ammo, rapidly turning around to face enemies immediately after finding ammo and human like navigation around buildings. These behaviors can be more fully appreciated in the video.
In future work we aim to further enhance the capabilities of the MAIL architecture by adding continuous actions for all rotations. This should provide a number of benefits when combined with the current MAIL architecture. Not only will it provide the agent with more fine grained motor control and reduce the size of the action space, it will also allow much higher quality expert data to be recorded by allowing data to be acquired using a mouse and keyboard or the analogue inputs on a game controller.
We will show more results in the coming weeks.
